欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
《hive学习笔记》系列导航
- 基本数据类型
- 复杂数据类型
- 内部表和外部表
- 分区表
- 分桶
- HiveQL基础
- 内置函数
- Sqoop
- 基础UDF
- 用户自定义聚合函数(UDAF)
- UDTF
本篇概览
本文是《hive学习笔记》系列的第四篇,要学习的是hive的分区表,简单来说hive的分区就是创建层级目录的一种方式,处于同一分区的记录其实就是数据在同一个子目录下,分区一共有两种:静态和动态,接下来逐一尝试;
静态分区(单字段分区)
先尝试用单个字段分区,t9表有三个字段:名称city、年龄age、城市city,以城市作为分区字段:
- 建表:
create table t9 (name string, age int) partitioned by (city string)row format delimited fields terminated by ',';- 查看:
hive> desc t9;OKname string age int city string # Partition Information # col_name data_type comment city string Time taken: 0.159 seconds, Fetched: 8 row(s)- 创建名为009.txt的文本文件,内容如下,可见每行只有name和age两个字段,用来分区的city字段不在这里设置,而是在执行导入命令的时候设置,稍后就会见到:
tom,11jerry,12- 导入数据的命令如下,可见导入命令中制定了city字段,也就是说一次导入的所有数据,city字段值都是同一个:
load data local inpath '/home/hadoop/temp/202010/25/009.txt' into table t9 partition(city='shenzhen');- 再执行一次导入操作,命令如下,city的值从前面的shenzhen改为guangzhou:
load data local inpath '/home/hadoop/temp/202010/25/009.txt' into table t9 partition(city='guangzhou');- 查询数据,可见一共四条数据,city共有两个值:
hive> select * from t9;OKt9.name t9.age t9.citytom 11 guangzhoujerry 12 guangzhoutom 11 shenzhenjerry 12 shenzhenTime taken: 0.104 seconds, Fetched: 4 row(s)- 前面曾提到分区实际上是不同的子目录,来看一下是不是如此,如下图,红框是t9的文件目录,下面有两个子目录city=guangzhou和city=shenzhen:
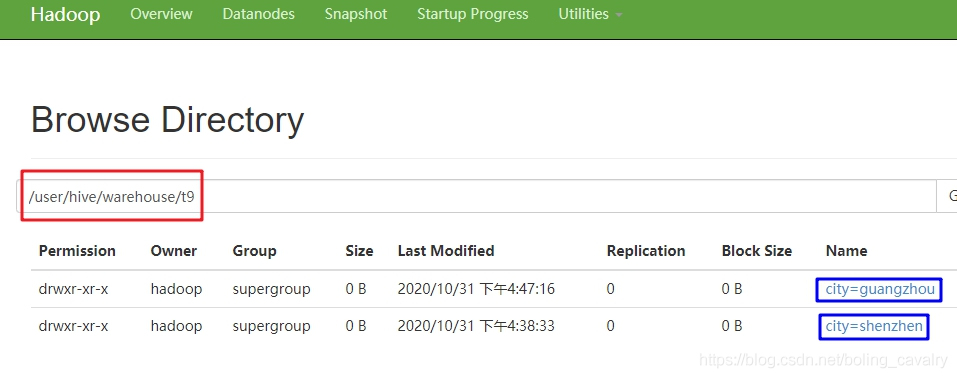
- 查看子目录里面文件的内容,可见每条记录只有name和age两个字段:
[hadoop@node0 bin]$ ./hadoop fs -ls /user/hive/warehouse/t9/city=guangzhouFound 1 items-rwxr-xr-x 3 hadoop supergroup 16 2020-10-31 16:47 /user/hive/warehouse/t9/city=guangzhou/009.txt[hadoop@node0 bin]$ ./hadoop fs -cat /user/hive/warehouse/t9/city=guangzhou/009.txttom,11jerry,12[hadoop@node0 bin]$以上就是以单个字段做静态分区的实践,接下来尝试多字段分区;
静态分区(多字段分区)
- 新建名为t10的表,有两个分区字段:province和city,建表语句:
create table t10 (name string, age int) partitioned by (province string, city string)row format delimited fields terminated by ',';- 上述建表语句中,分区字段province写在了city前面,这就意味着第一级子目录是province值,每个province子目录,再按照city值建立二级子目录,图示如下:
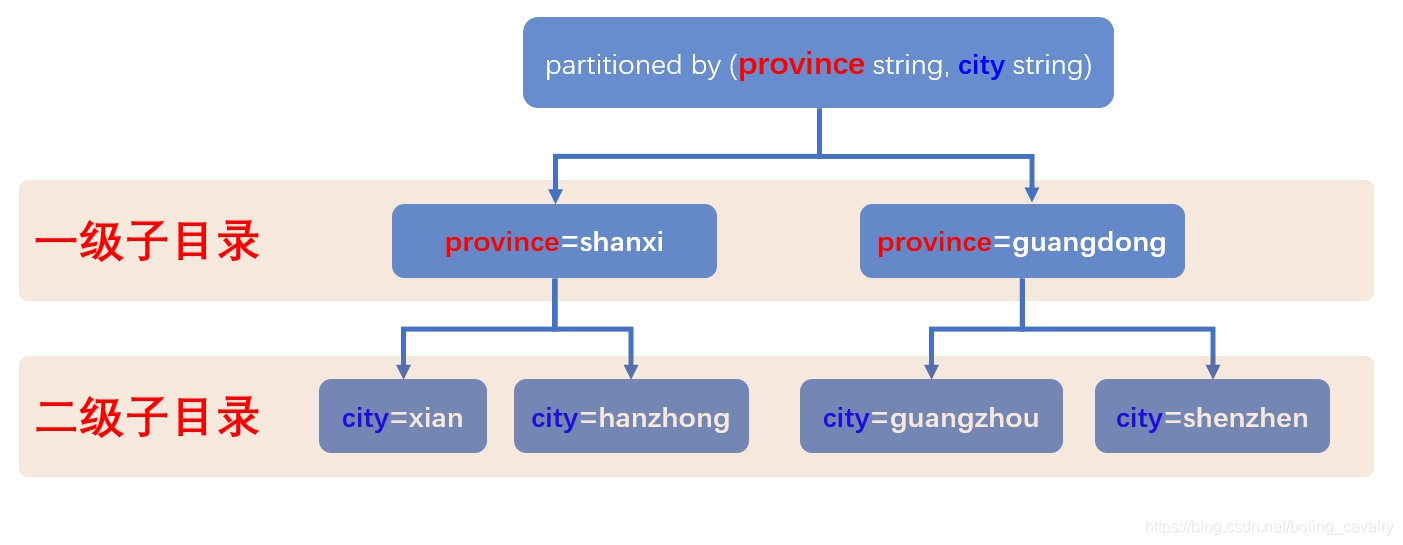
3. 第一次导入,province='shanxi', city='xian':
load data local inpath '/home/hadoop/temp/202010/25/009.txt' into table t10 partition(province='shanxi', city='xian');- 第二次导入,province='shanxi', city='xian':
load data local inpath '/home/hadoop/temp/202010/25/009.txt' into table t10 partition(province='shanxi', city='hanzhong');- 第三次导入,province='guangdong', city='guangzhou':
load data local inpath '/home/hadoop/temp/202010/25/009.txt' into table t10 partition(province='guangdong', city='guangzhou');- 第四次导入,province='guangdong', city='shenzhen':
load data local inpath '/home/hadoop/temp/202010/25/009.txt' into table t10 partition(province='guangdong', city='shenzhen');- 全部数据如下:
hive> select * from t10;OKt10.name t10.age t10.province t10.citytom 11 guangdong guangzhoujerry 12 guangdong guangzhoutom 11 guangdong shenzhenjerry 12 guangdong shenzhentom 11 shanxi hanzhongjerry 12 shanxi hanzhongtom 11 shanxi xianjerry 12 shanxi xianTime taken: 0.129 seconds, Fetched: 8 row(s)- 查看hdfs文件夹,如下图,一级目录是province字段的值:
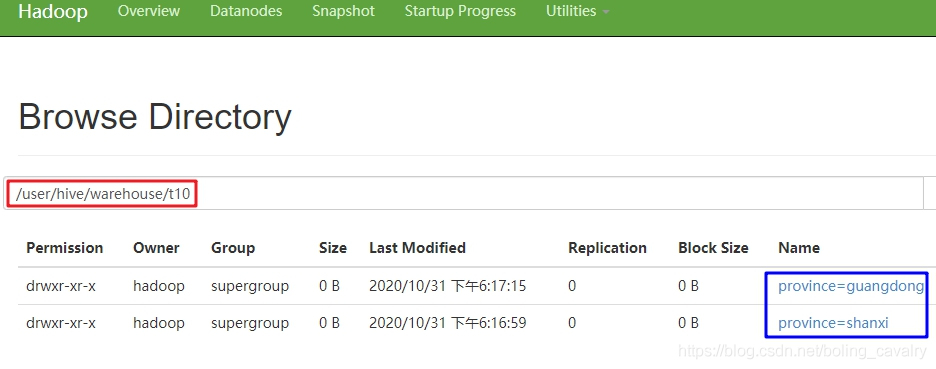
- 打开一个一级目录,如下图,可见二级目录是city的值:
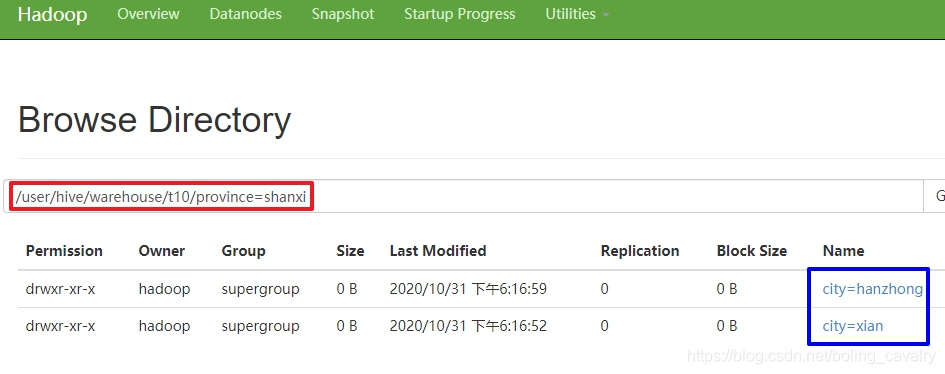
10. 查看数据:
[hadoop@node0 bin]$ ./hadoop fs -cat /user/hive/warehouse/t10/province=shanxi/city=hanzhong/009.txttom,11jerry,12- 以上就是静态分区的基本操作,可见静态分区有个不便之处:新增数据的时候要针对每一个分区单独使用load命令去操作,这时候使用动态分区来解决这个麻烦;
动态分区
- 动态分区的特点就是不用指定分区目录,由hive自己选择;
- 执行以下命令开启动态分区功能:
set hive.exec.dynamic.partition=true- 名为hive.exec.dynamic.partition.mode的属性,默认值是strict,意思是不允许分区列全部是动态的,这里改为nostrict以取消此禁制,允许全部分区都是动态分区:
set hive.exec.dynamic.partition.mode=nostrict;- 原文转载:http://www.shaoqun.com/a/841141.html
跨境电商:https://www.ikjzd.com/
houzz:https://www.ikjzd.com/w/236
1号团:https://www.ikjzd.com/w/2263
heap:https://www.ikjzd.com/w/2012
欢迎访问我的GitHubhttps://github.com/zq2599/blog_demos内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;《hive学习笔记》系列导航基本数据类型复杂数据类型内部表和外部表分区表分桶HiveQL基础内置函数Sqoop基础UDF用户自定义聚合函数(UDAF)UDTF本篇概览本文是《hive学习笔记》系列的第
square:https://www.ikjzd.com/w/2106
jpgoodbuy:https://www.ikjzd.com/w/1553
敦煌网12月9日正式上线商户服务能力评级!:https://www.ikjzd.com/articles/112021
亚马逊卖家中心平台上线"定价状况"页面/阿里巴巴国际站发布《中国中小企业跨境电商白皮书》:https://www.ikjzd.com/articles/112024
图文实操:数据化运作打造极速爆款!:https://www.ikjzd.com/articles/112026
浅析:优秀的跨境电商卖家到底是怎么做的?:https://www.ikjzd.com/articles/112027
男朋友让我张开腿给他吃 舌头伸进我下面我很爽:http://lady.shaoqun.com/a/247755.html
解开胸罩揉着她的乳尖 我被6个男人玩到早上:http://www.30bags.com/m/a/249707.html
无意中发现了女邻居的小秘密,让我更爱她了:http://lady.shaoqun.com/a/397659.html
我的邻居(美女):http://lady.shaoqun.com/a/397660.html
小说:一个美丽邻居的故事:http://lady.shaoqun.com/a/397661.html
小说:光鲜的邻居请我吃饭。我走后,她偷偷溜进来问你一件事:http://lady.shaoqun.com/a/397662.html
No comments:
Post a Comment