mysql
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
mysql结构
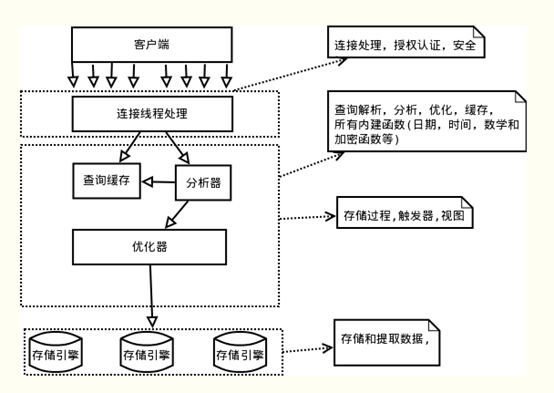
如上图所示,可分为用户连接线程 -> 服务层 -> 存储引擎
用户连接线程:处理客户端连接、授权、用户认证等。
服务层:处理sql语句的解析、缓存的处理和函数的实现等
存储引擎:对于数据的存储和提取(innodb、NDB Cluster支持事务,Mylsam、Memory不支持事务)。
如无特殊说明,后文中描述的内容都是基于InnoDB。
ACID事务特性
mysql由start transaction标识事务的开启,commit提交事务,rollback回滚事务,mysql在默认情况下开启事务,即autocommit模式,在这种模式下,每一个sql语句都会被当成一个事务执行提交操作。当然也可以将autocommit的开关关上,需要注意的事,autocommit参数针对的事连接,修改参数只会对当前连接生效,如需全局修改,请修改启动配置文件。
mysql当中,当执行一些特殊的语句的会后,会强制事务的提交,比如DDL语句(create table/drop table/alter/table),常用的增删改查操作都不会强制提交事务
- 原子性(Atomicity)
原子性是指一个事务不可分割的一个工作单位,要么都成功,要么都失败。针对单个事务而言
实现原理:undo log(回滚日志,由存储引擎实现)
当事务对数据库进行修改时,innodb会生成对应的undo log记录,记录sql执行相关信息。当事务失败调用rollback回滚时,会根据undolog中的信息进行反向操作,将数据回滚到事务开启之前的状态。
- 一致性(Consistency)
一致性指的是事务执行前后数据的完整性没有被破坏,包括实体完整性(如行的主键存在且唯一)、列完整性(如字段的类型、大小、长度要符合要求)、外键约束、用户自定义完整性(如转账前后,两个账户余额的和应该不变)等等。
一致性是事务的终极目标,其他三个特性都是为一致性所服务的
数据库实现一致性的措施体现:
不允许向整形列插入字符串值、字符串长度不能超过列的限制等
- 隔离性(Isolation)
隔离性指的是多个事务同时执行的时候,每个事务内部都应该与其他事务是隔离的,不能互相干扰。
数据库的隔离级别:读未提交(RU)、读已提交(RC)、可重复读(RR)、序列化也叫串行化(S)
实现原理:读读之间(MVCC多版本并发控制协议)、读写之间(锁机制)
1、MVCC:MVCC是一种乐观锁的体现,主要是通过两个隐藏列实现(事务版本号和undolog指针,也是undolog版本链),用户在某一时刻对整个事务系统进行快照,之后再进行读操作时,会将读取到的事务中的事务版本号和快照比较,从而判断数据对该快照是否可见,即对打快照时的事务是否可见。RR隔离级别下,事务在事务开始的时候进行快照动作,一直到事务提交都不会重新进行快照。RC则是每次select操作之前会重新建立快照,这就导致RC可能会在第二次select的时候读到其他事务提交得数据,所以RC情况下可以避免脏读问题可是无法避免重复读和幻读问题。
2、锁机制:mysql锁可以分为共享锁(lock in share mode)、排它锁(for update)、意向锁(意向共享和意向排他)、间隙锁(Gap lock),共享锁、排它锁是行锁,锁粒度小,性能好,意向锁是表锁,是数据库自身的行为,不需要人工干预,在事务结束后会自行解除,多用在innodb当中,意向锁主要解决事务开始时遍历所有行的锁持有情况从而导致性能较低的问题,事务在检查行锁之前会检查意向锁是否存在,存在则阻塞线程.
意向锁协议:
- 事务要获取表A某些行的S锁必须要获取表A的IS锁(意向共享锁)
- 事务要获取表A某些行的X锁必须要获取表A的IX锁(意向排他锁)
间隙锁:
innodb下间隙锁的产生需要产生三个条件:
1、隔离级别为RR(mysql默认,不改即为这个)
2、当前读(非快照读)
3、查询条件能够走索引(这里提一句:mysql行锁(间隙锁也是行锁)锁的是索引,所以当查询未使用索引的情况下,innodb会使用表锁,这就会导致一些使用相同索引键的查询也会出现锁冲突)
注意:innodb使用一个相等条件请求对一个不存在的记录加锁的时候,也会产生间隙锁
间隙锁的作用:
当前读幻读的解决方法:间隙锁可以锁定一个范围内的多条数据,防止事务执行的时候其他事务往这个范围内插入数据,导致幻读,这是主要目的。
- 持久性(Durability)
持久性指的是事务一单提交,它对数据库产生的改变应该是持久的(单个事务而言).
实现原理:redo log(重做日志,存储引擎实现)
在innodb当中,数据是存放在磁盘上的,但是如果每次查询数据都需要读磁盘的话,效率会相当低。为此,innodb提供了一个缓存机制--Buffer Pool(简称BP),BP中包含了磁盘中部分数据的映射,作为访问数据库的缓存。
当读数据的时候,先读BP,BP没有在读磁盘,然后将数据放入BP。
当写数据的时候,先写BP,BP会将数据定期刷新到磁盘当中(刷脏)。
上面写数据就会产生一个问题,当我们的机子死机了,BP数据还未刷到磁盘中那数据不就丢失啦?事务的持久性就得不到保证
为了解决这个问题:redo log 引入解决这个问题:
当数据修改时,会先记录在redo log 中。然后再写入BP中,当事务提交的时候,就会调用fsync接口对redolog进行刷盘(落磁盘),如果mysql宕机,就可以在重启的时候读取redolog的日志恢复数据库中的数据.
既然redolog也要进行磁盘IO,为什么比BP快呢?
两个原因:
1、BP是随机IO,每次修改的位置随机,redoLog属于追加操作,顺序IO.
2、BP是以页(Page)为单位进行磁盘操作的,但是redolog只是做真正需要写入的部分,相对BP来讲,会少很多无效的IO.
最后提一嘴binog和redo log的区别:
1、redo log存储引擎实现、binlog服务层实现(可参照第一张图,不太擅长画图,sorry……)
2、redo log写入的时机比较多,各种修改都会触发,只是在事务提交的时候落磁盘而已。binlog则只会在事务提交的时候写入。
3、binlog为二进制日志,根据参数不同可能是sql或者数据。redolog则是物理日志,内容基于Page。
第一次写一篇比较完整的博客,完全根据自己的想法走,要是哪个位置写的不太对,欢迎大家一起探讨提高,感谢每一个路过的人。
mysql浅谈
更好解决物流问题、 一淘比价网、 ask me、 这三封电子邮件可帮你赶走90%的跟卖卖家!!!、 2019亚马逊全球开店拉开序幕,这些账号注册细节你可得注意了、 跨境电商独立站卖家如何开启Dropshipping模式、 返校季又双叒叕要来了!卖家该如何做准备?、 Pledgemusic、 亚马逊日本站官方分享大会、 选品规划、 拍怕、 速卖通新店如何抓住新品流量快速单品突破、 亚马逊批量上传产品库存文件模板的填写办法、 2019年起,所有进入澳大利亚的中国商品将免关税!这份电商报告揭露商机!、 亚马逊2019下半年旺季爆单思路、 漂亮!Anker傲基泽宝在CES亮相新品、
No comments:
Post a Comment